On Quality of Generated Adversarial Examples and How to Set Attack Contraints
Title: Reevaluating Adversarial Examples in Natural Language
Paper EMNLP Findings
Abstract: State-of-the-art attacks on NLP models lack a shared definition of a what constitutes a successful attack. We distill ideas from past work into a unified framework: a successful natural language adversarial example is a perturbation that fools the model and follows some linguistic constraints. We then analyze the outputs of two state-of-the-art synonym substitution attacks. We find that their perturbations often do not preserve semantics, and 38% introduce grammatical errors. Human surveys reveal that to successfully preserve semantics, we need to significantly increase the minimum cosine similarities between the embeddings of swapped words and between the sentence encodings of original and perturbed sentences.With constraints adjusted to better preserve semantics and grammaticality, the attack success rate drops by over 70 percentage points.
Our Github on Reevaluation: Reevaluating-NLP-Adversarial-Examples Github
Citations
@misc{morris2020reevaluating,
title={Reevaluating Adversarial Examples in Natural Language},
author={John X. Morris and Eli Lifland and Jack Lanchantin and Yangfeng Ji and Yanjun Qi},
year={2020},
eprint={2004.14174},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
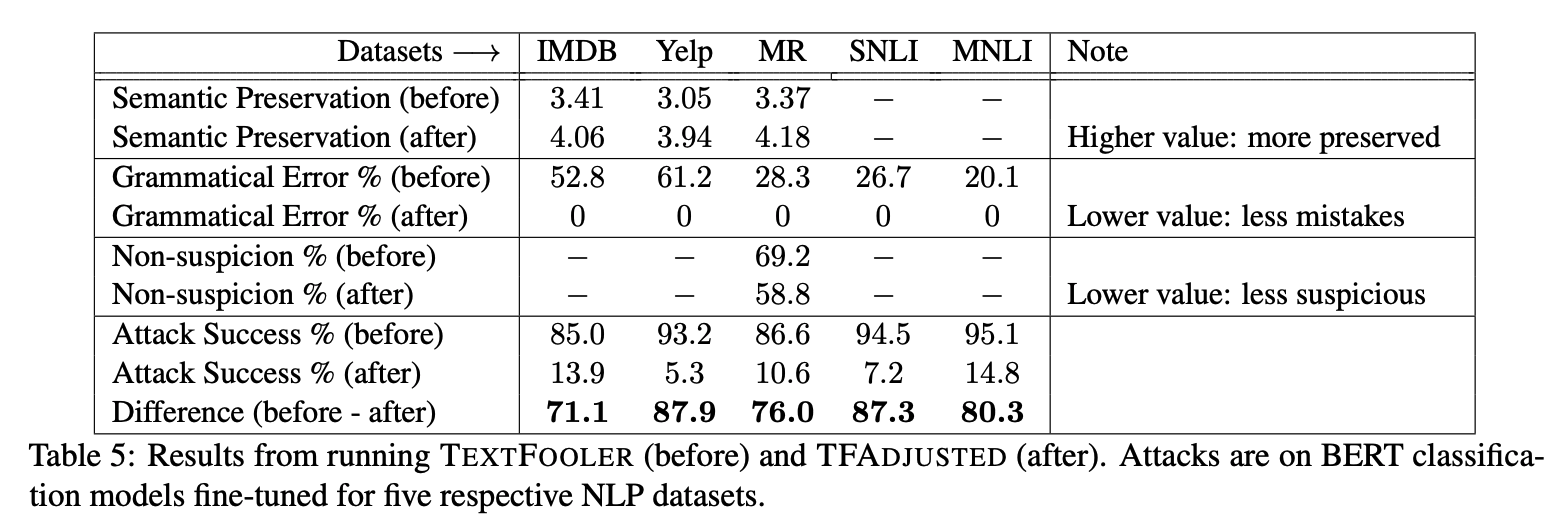
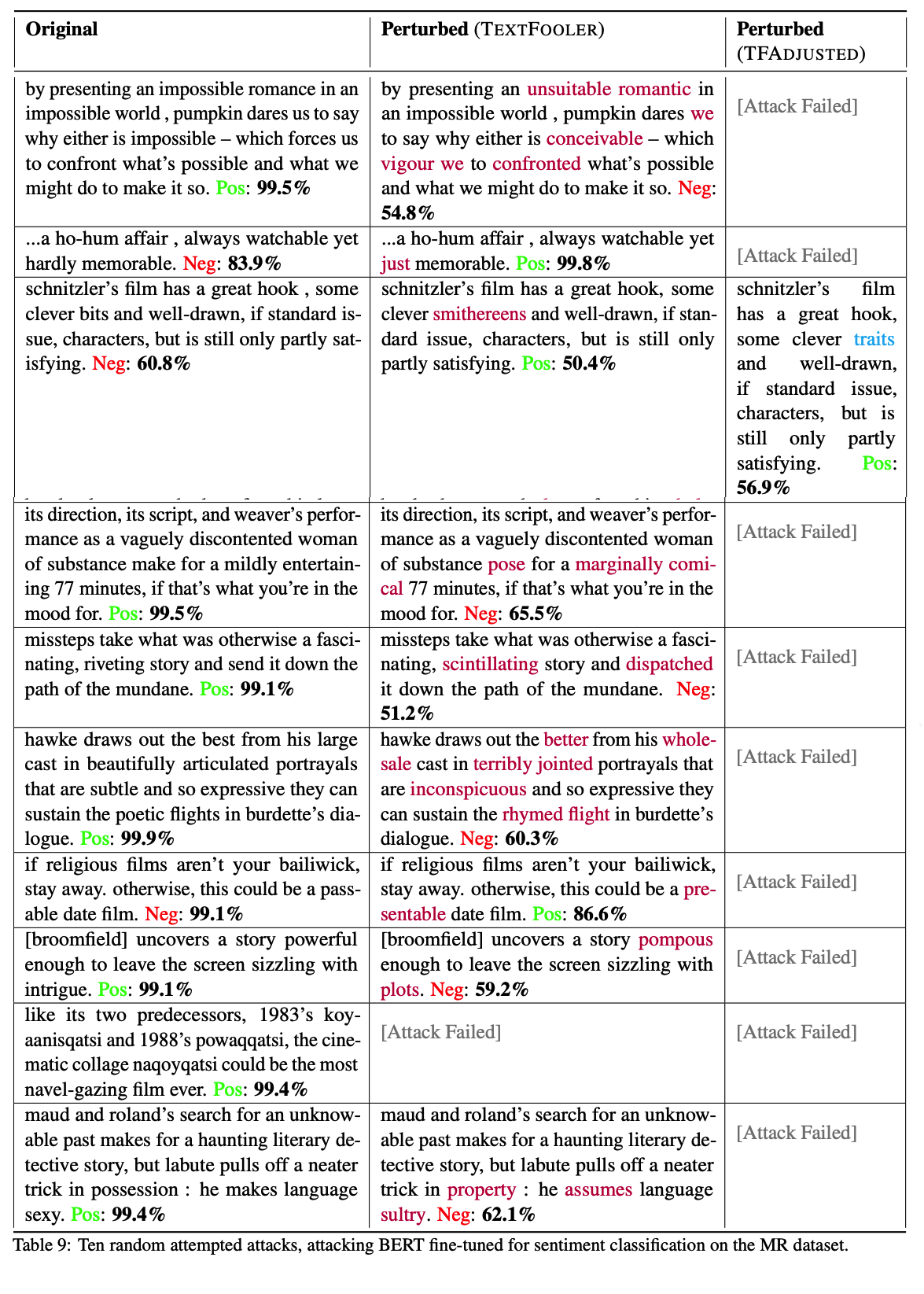
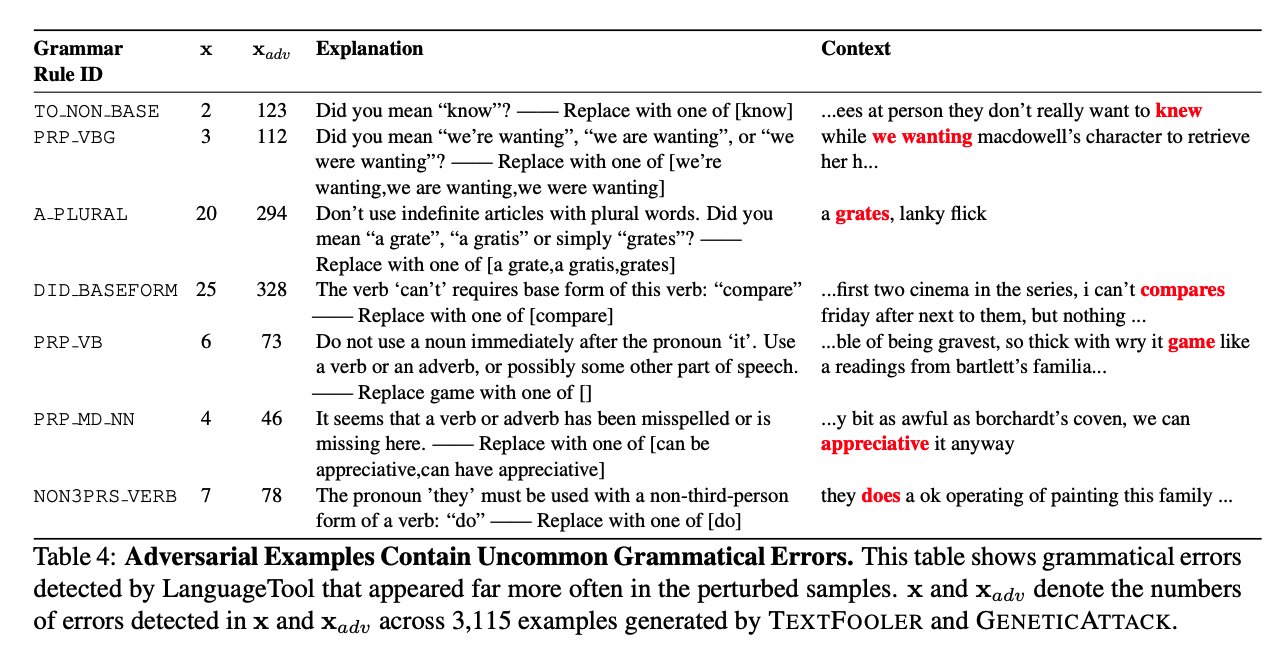
Some of our evaluation results on quality of two SOTA attack recipes
As we have emphasized in this paper, we recommend researchers and users to be EXTREMELY mindful on the quality of generated adversarial examples in natural language
We recommend the field to use human-evaluation derived thresholds for setting up constraints

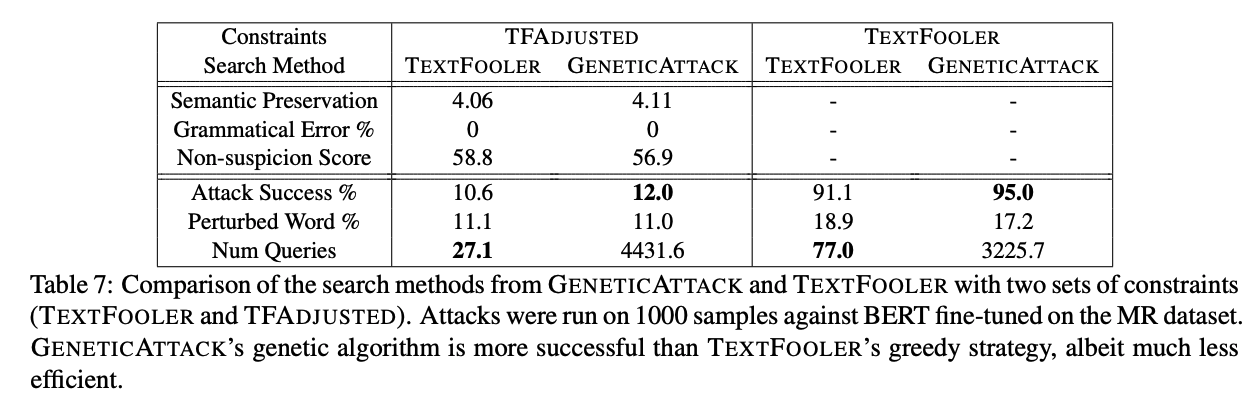
Some of our evaluation results on how to set constraints to evaluate NLP model’s adversarial robustness